Der Titel dieses Artikels entspricht grob gesagt meinem Betätigungsfeld als (teilzeit-) wissenschaflticher Mitarbeiter am Institut für Allgemeinmedzin der Medizinischen Hochschule Hannover. Vor dem Hintergrund war ich vom 26.-27.10.2011 in Göttingen im Freizeit In (Bild), um an dem gemeinsamen Jahretreffen von HL7-Deutschland und IHE teilzunehmen.

Die HL7-Treffen waren in den letzten Jahren ein sehr gutes Forum, um sich einen praxisnahen Überblick über den Stand der (Daten-)Technik im Gesundheitswesen im deutschsprachigen Raum zu verschaffen – so auch dieses Mal.
Im Allgemein scheint sich technisch in letzter Zeit nicht sehr viel Neues ergeben zu haben, zumindest was die tatsächliche Implementierung in der Praxis betrifft, dennoch ergaben sich einige Denkanstöße für die Zukunft. Einige Aspkete habe ich nachstehend aufgeführt.
Der aktuelle Stand der Dinge (aus der Sicht von jemanden, der gerne mit hausärztlichen Routinedaten unabhängig forschen möchte und dafür „Schnittstellen“ sucht …. ):
1. Stationärer Sektor und niedergelassenen Praxen sind technisch noch nicht ausreichend miteinander verschmolzen, noch immer gibt es hauptsächlich HL7 auf der einen (klinischen) und xDT auf der anderen (ambulanten) Seite.
2. HL7 Version 2.x und Kommunikationsserver (Cloverleaf, Mirth, Ensemble, …) sind nach wie vor das Maß der Dinge für den Datenaustausch im KIS-Umfeld (Siemens, Agfa Orbis, iSoft, …)
3. In der Primärversorgung (z. B. niedergelassene Allgemeinmediziner… ) war in den letzten Jahren eine Marktonzentration auf wenige Hersteller von Arztsystemen (Medistar, Turbomed, … ) zu beobachten. Die Hersteller (Compugroup, Medatixx, …) forcieren die Etablierung eigener Produkte zur elektronischen Patientenakte (EPA) oder Schnittstellen / Kommunikationslösungen, wie Vita-X/CGM-Life oder comdoxx. Eine flächendeckende Lösung zum einheitlichen, intersektoralen, interoperablen Datenaustausch scheint nach wie vor nicht in Sicht. Der elektronische Arztbrief auf Basis von HL7/CDA scheint zwar ein guter Start zu sein, den Ausführungen auf der Tagung zufolge jedoch noch verbesserungsfähig vom Masseneinsatz noch weit entfernt. Vor diesem Hintergrund scheinen für die Allgemeinmedizin der Continuity of Care Record (CCR) und dessen HL7/CDA-konforme Umsetzung in das Continuity of Care Document (CCD) relevant zu sein.
3. Es darf bezweifelt werden, das die elektronische Gesundheitskarte, außer einer bundesweiten PKI-Struktur, noch irgendein weiteres „Gesundheits-Problem“ nachhaltig löst, was allerdings auch nur bedingt ihre Aufgabe ist. Dennoch ist eine einheitliche Infrastruktur Grundvoraussetzung für sinnvolle, gemeinsame Anwendungen, die auf dieser Struktur aufbauen und heute vielleicht noch garnicht bekannt sind.
Die interessantesten Denkanstösße aus Tagung und Tutorials ergaben sich für mich vor allem für das Forschungsumfeld:
1. CDISC
Vertreten durch Pierre-Yves Lastic wurde neben CDSIC auch das Projekt EHR4CR vorgestellt (Bild).

CDISC bietet, getrieben durch die Notwendigkeit der Pharmaindustrie Studiendaten im SDTM-Format bei der FDA einzureichen, viele weit entwickelte „Bausteine“ zur Erfassunng und Strukturierung von Daten und zur Nutzung in der klinischen Forschung, beispielsweise das BRIDG-Modell und CDASH. Aktuelle Entwicklungen, beispielweise der Abstimmung mit dem HL7-RIM-Modell, machen Hoffnung, dass sich die „Bausteine“ weiter verbreiten und vielleicht auch von der klinischen Forschung in die Versorgungsforschung abfärben, wo es noch an einheitlichen Modellen mangelt.
2. IHE-Profile
Im Tutorial zu HL7 und IHE gab es von Herrn Heitmann einen guten Überlick, wie die aktuellen Entwicklungen, Institutionen und Standardisierungsbemühungen im Gesundheitswesen einzuordnen sind. Eine übergeordnete Sonderrolle wurde dabei IHE zugedacht. Die Initiative definiert allgemeine Anwendungsfälle im Gesundheitswesen und schlägt hierfür Lösungen in Form von „best-practices“ auf Basis aktueller Technologien vor (Profile). So können einerseits für bestimmte Problemszenarien zielsicher passende Produktlösungen im Markt identifiziert werden. Andererseits werden allgemeingültige Prozesse defineirt, die für jedermann einsehbar, anpassbar und nutzbar sind. Insbesondere scheint es (neuerdings) bei den Profilen zu Qualitätssicherung, Forschung und Public Health zunehmende Aktivitäten zugeben. Dies ist möglicherweise eine gute Anlaufstelle für die akademische Versorgungsforschung, sich praxisnah einzubringen.
3. EPA & Co.
Anscheinend waren einige Teilnehmer die akademische Diskussion, wie eine elektronische Patientenakte (EPA) definiert und implementiert wird, oder ob es doch besser eine elektronische Fallakte (EFA) sein solle und wie das alles datenschutztechnisch abzubilden ist bereits leid.Vor diesem Hintergrund fand ich den Vortrag von Björn Bergh aus Heidelberg sehr interessant, der darauf hinwies, dass die letzten Versuche zur Etablierung einer persönlichen Gesundheitsakte durch große Mitspieler (Google Health, ICW Life Sensor, Microsoft Health Vault, Barmer) allesamt gescheitert sind. Neben Akzeptanzproblemen und fehlenden Märkten, scheint vor allem der Datenschutz in Deutschalnd bremsende Wirkung zu haben. Als Lösnug wurde ein Verfahren skizziert, welches einen zentralen Master Patient Index (MPI) nutzt und die Vorteile des Personal Health Records (PHR), z. B. die Selbstbestimmungsrecht des Patienten, mit den Vorteilen eines zentralen Electronic Health Record (EHR), z. B. beim Datenschutz, kombiiniert. Vielleicht lassen hieraus auch Szenarien für die Versorgungsforschung ableiten.
4. Semantic & Co.
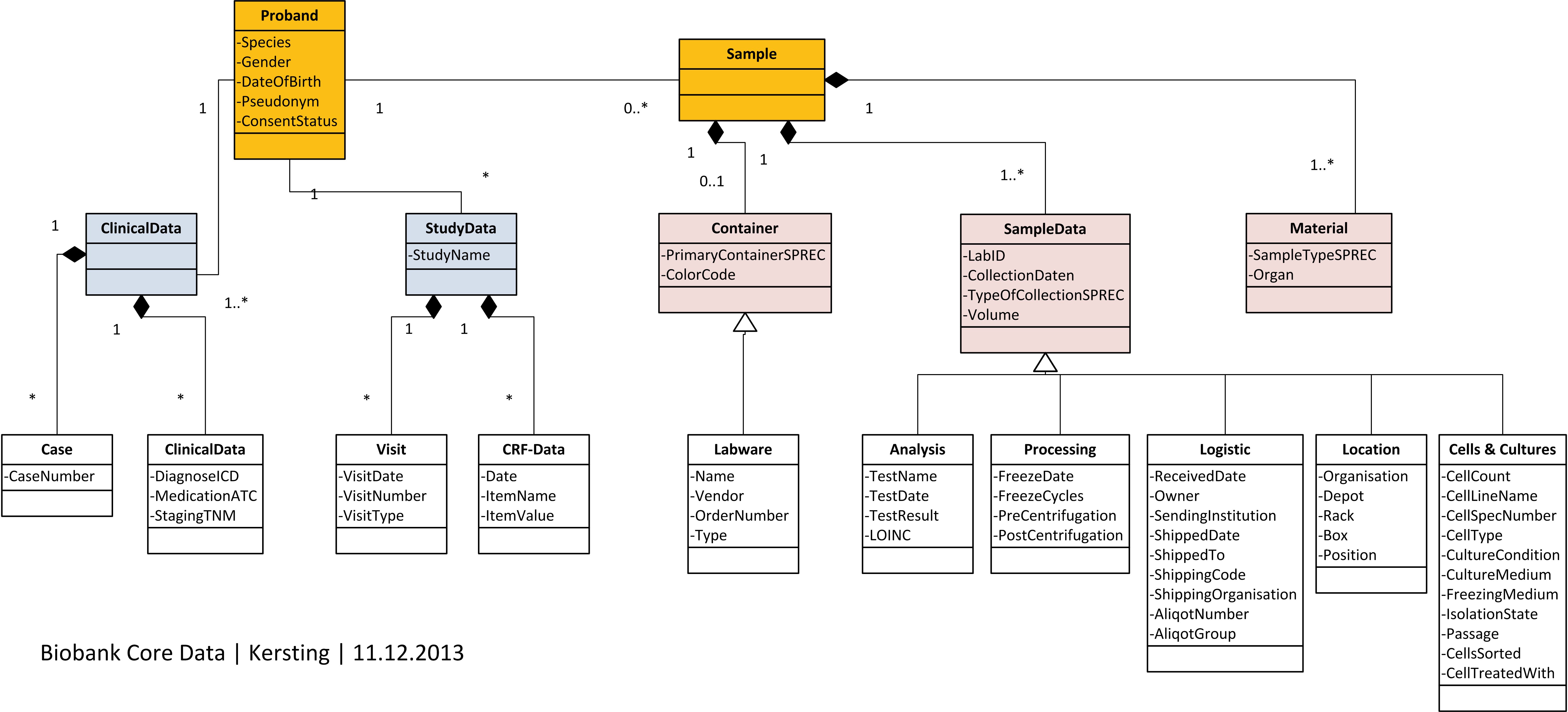
Für eine intersektorale, semantische interoperable Kommunikation Bedarf es einiger Grundbausteine, für die die Wissensrepräsentation noch einige mehr. Einheitliche Modelle und Terminologien wären schön. Aber ist das RIM immer passend oder brauche ich mein eigenes Modell? Muss es Snomed sein? Reicht ICD? Brauch ich Archetypen? Wie bilde ich medizinisches Wissen ab? … Gut fand ich in diesem Kontext die sinngemäße Aussage von Peter Adlassnig aus Wien im letzten Vortrag der Veranstaltung ..: „Wir haben es allen Bedenkenträgern zum Trotz einfach mal gemacht, die Bausteine sind ja da.“. Mit Arden haben er und seine Leute ein medizinisches Decision Support System (DSS) entwickelt und zur markreife gebracht. Viellecht wäre dies auch für die Allgemeinmediziner eine Möglichkeit, ihre Leitlinien einheitlich elektronisch zu implementieren. Unter anderem dafür wäre es extrem hilfreich, wenn die Behandlungsdokumetation etwas strukturierter als bisher erfolgen würde. Der direkteste Anknüpfungspunkt scheint mir zu sein, sich zunächst einmal darauf zu konzentrieren, neben der freitextlichen Dokumentation, zusätzlich alle Infomormationen zu kodieren, für die bereits etablierte Ordungssysteme existieren. Nach unseren bisherigen Routinedaten-Untersuchungen ist hier noch reichlich Luft nach oben.
So. Die Informationen waren zwar nicht alle von der HL7/IHE-Tagung, aber macht ja nix 😉